What shipped was a foundation. What it established was a product stance.
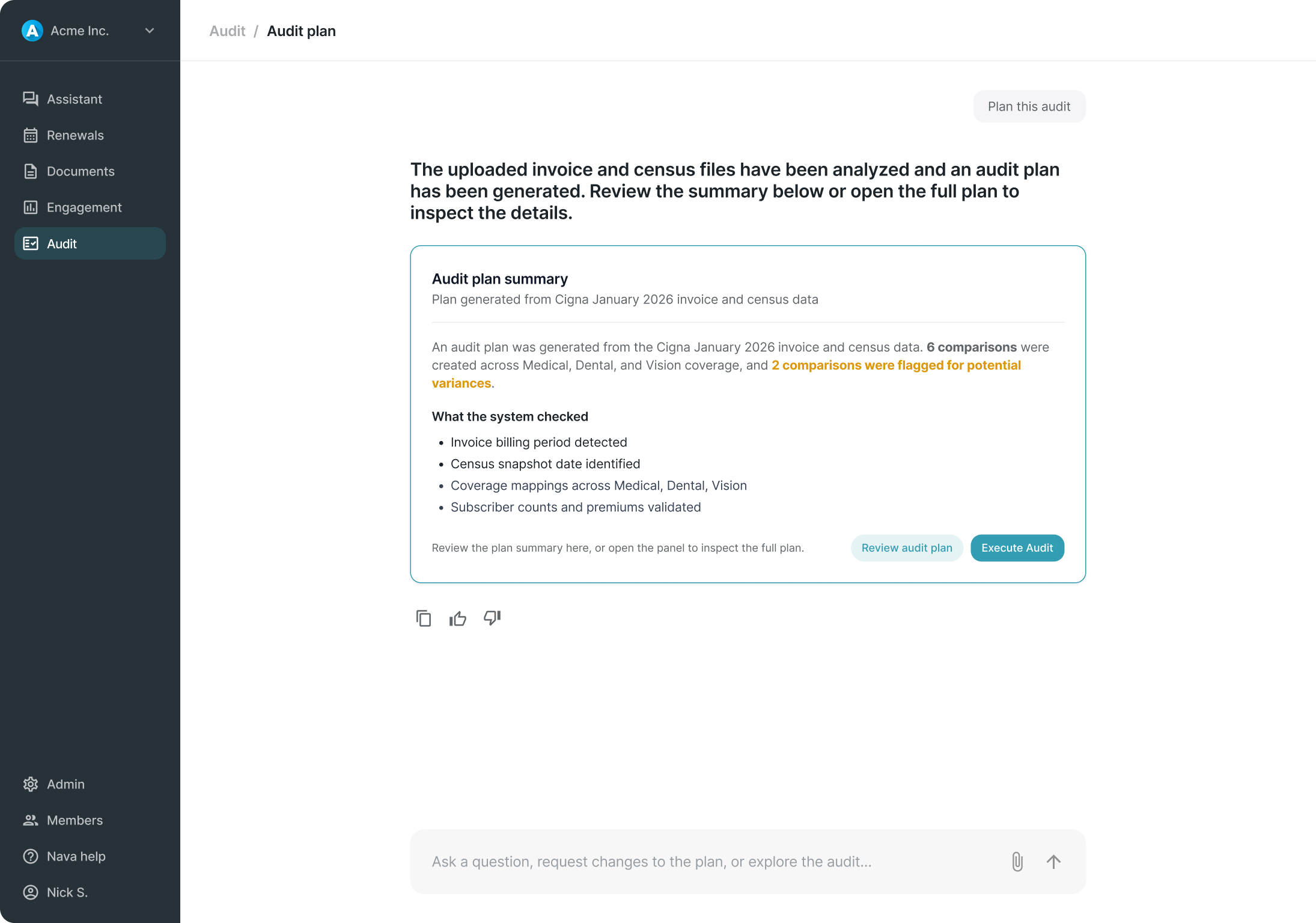
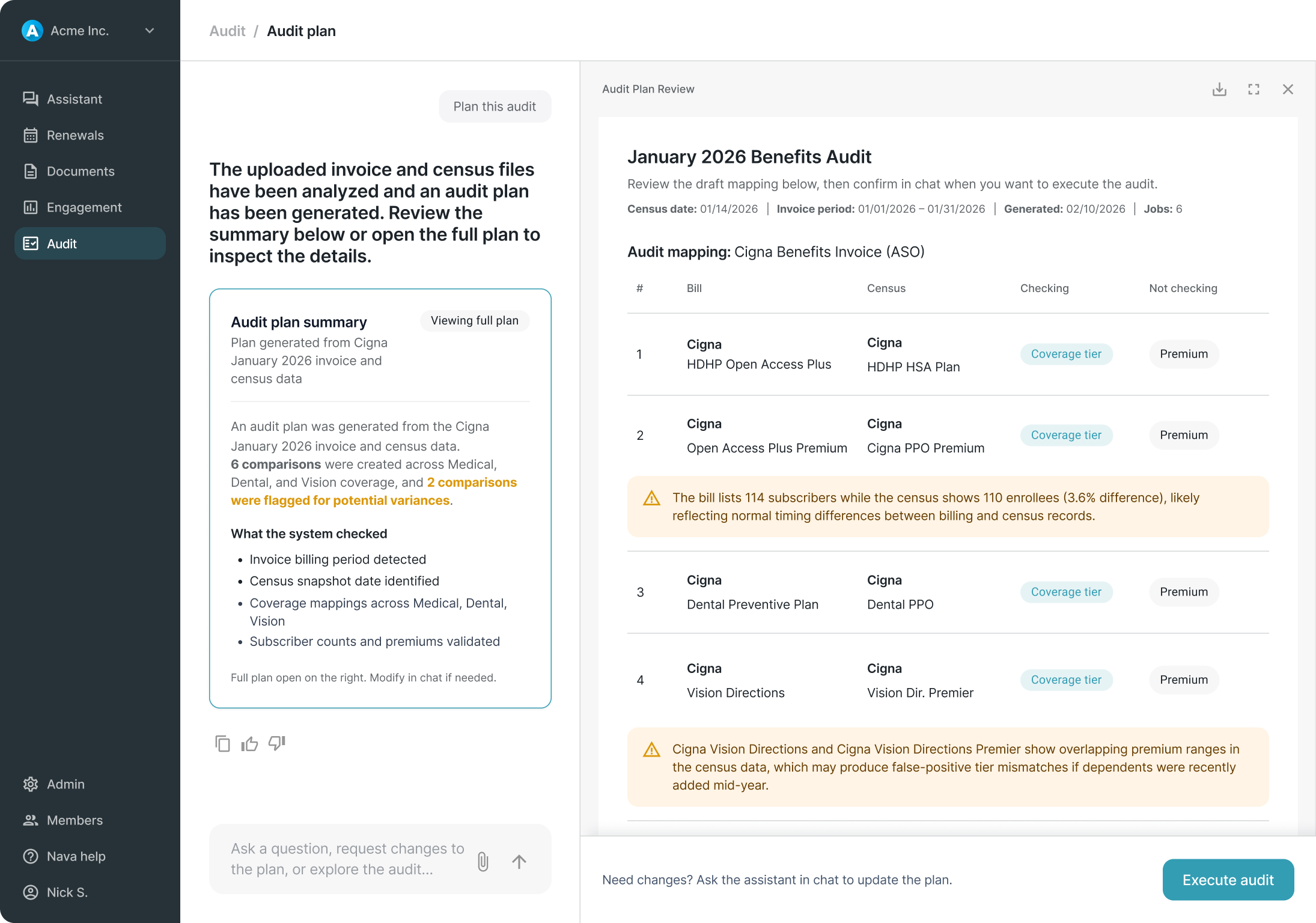
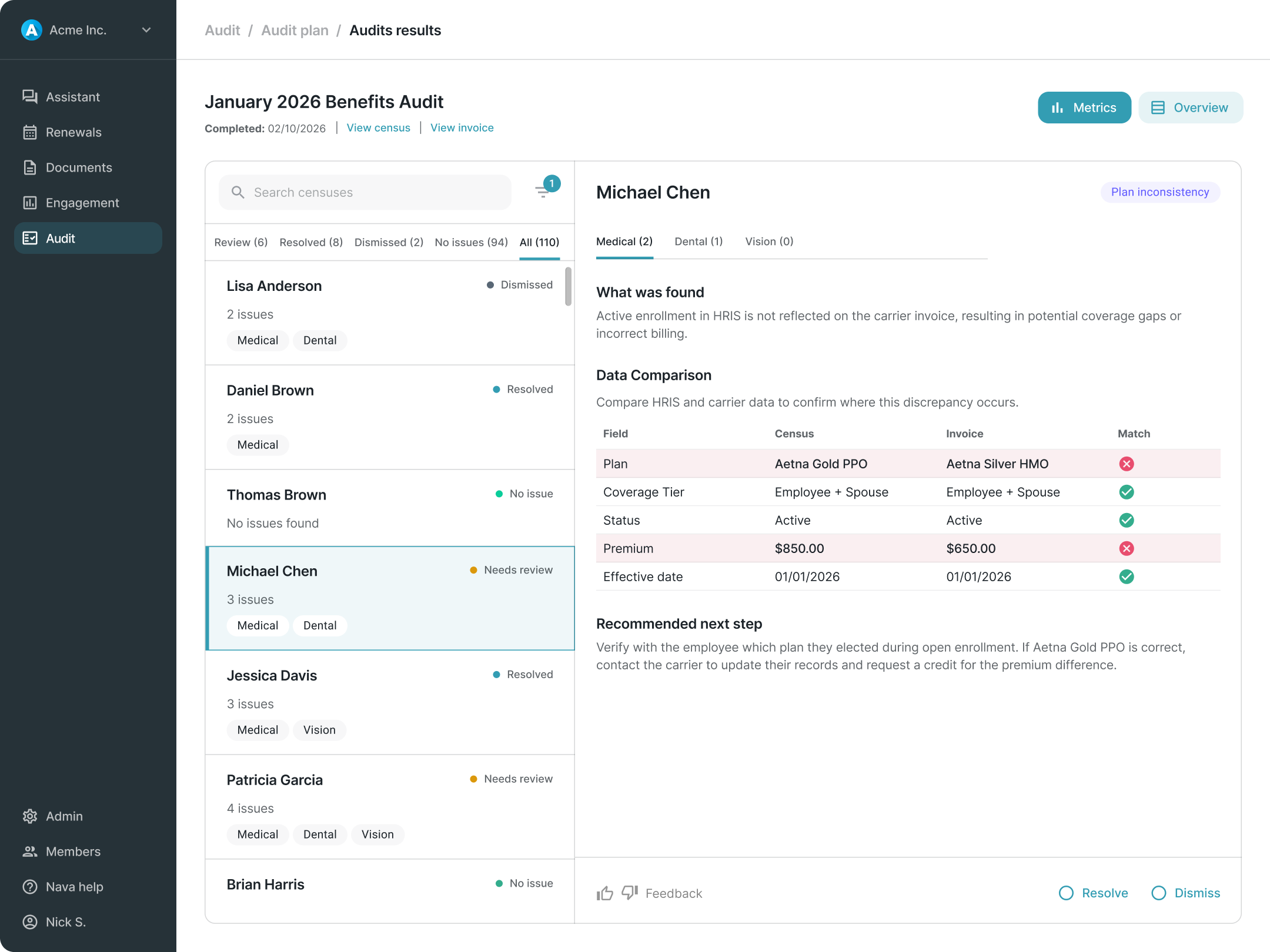
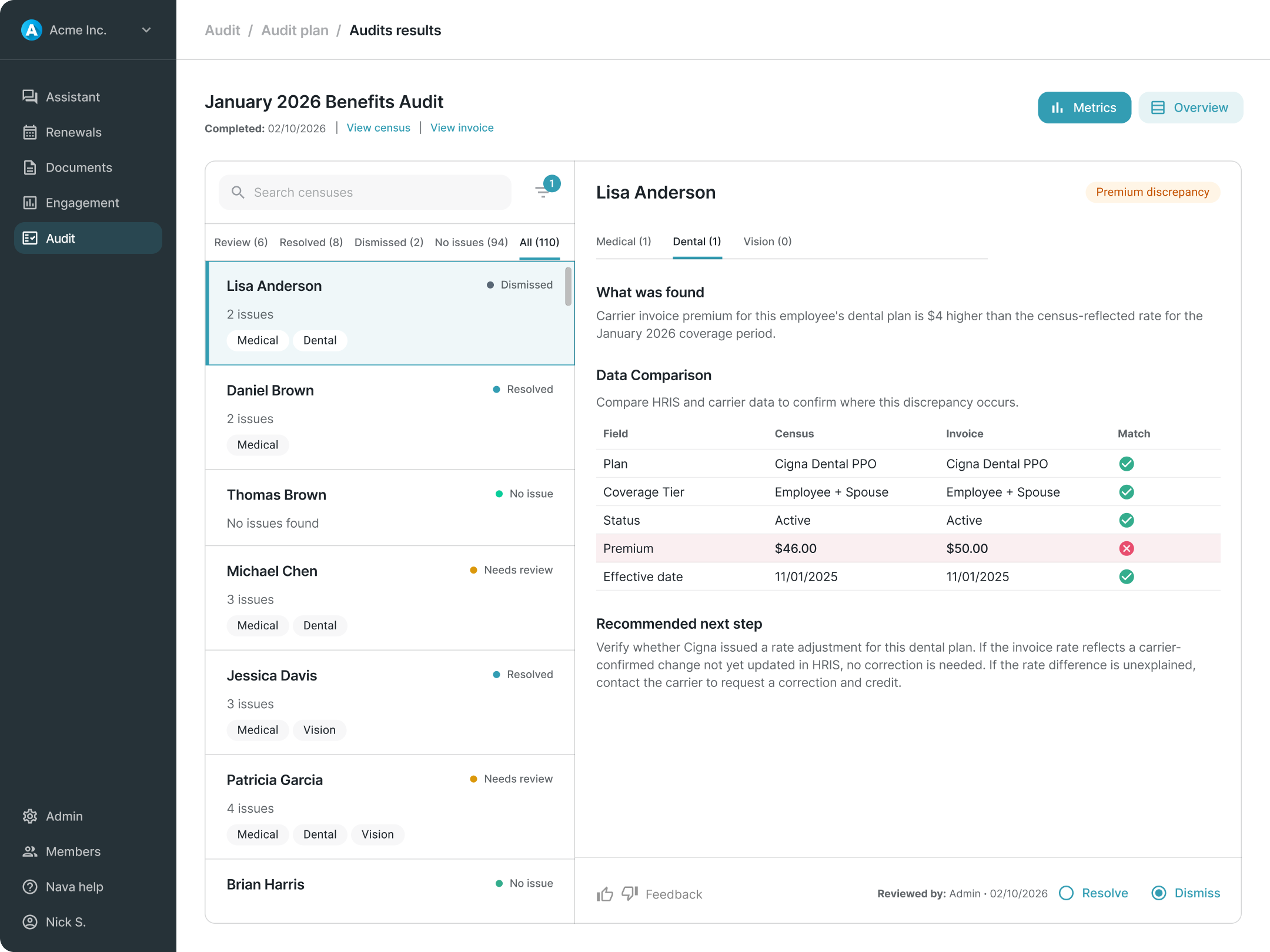
Usability testing confirmed that earlier designs, which exposed too much system detail during planning and used more narrative descriptions in results, created friction the final model resolved. The summary-first planning approach and simplified triage list both emerged from consistent feedback that earlier iterations were harder to follow and slower to navigate.
There are no post-launch metrics. But the experience was designed to generate them, particularly around whether users engage with the full plan before executing or proceed directly from the summary.
The broader contribution was establishing that the right product stance for v1 was a review-and-decision model rather than a task management system. A call that kept scope in check, avoided overbuilding on assumptions, and left room for the product to learn what a more mature system should actually look like.